Designing Data-Intensive Applications: A Look at Data Storage and Retrieval
- _ shli001@uw.edu
- Dec 6, 2020
- 7 min read


Introduction
Data is at the center of many challenges in system design today. Knowing how data are stored and retrieved in computer systems is very important for the design and implementation of data-intensive applications. Databases, such as MySQL and DynamoDB, are designed for the storage and retrieval of data. On the most fundamental level, a database needs to do two things: when you give it some data, it should store the data, and when you ask it again later, it should give the data back to you. A storage engine is the underlying software component that a database management system uses to create, read, update, and delete data from a database. While you are probably not going to implement your own storage engine from scratch, you do need to select a storage engine that is appropriate for your applications, from the many that are available. In order to tune a storage engine to perform well for your kind of workload, it is helpful to know how some of these databases handle your data behind the curtain.
In this post, I will discuss the data structures used internally by two families of storage engines: log-structured and page-oriented. I will also compare the data structures so that you can better understand the tradeoffs between them. By the end of this post, you should be able to name three data structures commonly used by storage engines.
Log-Structured Storage Engine
Consider the world’s simplest database, which is capable of storing and retrieving data using a key that uniquely identifies the record.
#!/bin/bash
lookup() {
echo "$1,$2" >> database
}
store() {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}Note: In order to use this database, copy and paste everything into an empty text file and rename the file to database.sh. Then, open a command prompt, cd to the file's directory, and run source database.sh. To store a key and value, type store [key] [value] in your command prompt, and hit enter. For example, store score 100 associates the key score to the value 100. To retrieve a value using a key, type lookup [key] in your command prompt, and hit enter. You might also need to create an empty file called database for it to work.
The basic idea of how this database works is that it appends to a text file (called database) every time you write and greps that text file for the latest update every time you read.
The underlying storage format is very simple: a text file where each line contains a key-value pair separated by a comma. Every call to store() appends the key-value pair to the end of the file. This means if you update a key, the old value for that key is not overwritten, and instead, you have to look at the last occurrence of the pair in the file to know its latest value.
This toy database is quite performant for small workloads given its simplicity. The reason why it has good performance is that appending to a file is usually very efficient. Similar to what our toy database is using, many real databases internally use a log, which is an append-only data file, to store the data. Storage engines that store data in a log are called log-structured storage engines.
On the other hand, this toy database has terrible performance if there are many entries in the database. For example, in order to look up the latest value of a given key, the entire file must be scanned from beginning to end, which means the cost of the lookup is O(n) with n being the total number of entries. Intuitively speaking, this means if you double the number of entries n in the database, it would take twice as long to look up a key. This is not good because databases are expected to handle a large quantity of data, and our toy database would soon be rendered useless as the time it takes for a lookup grows out of control.
Hash Indexes
To improve the performance of our toy database for a large number of entries, we can use an in-memory dictionary to speed up the lookup. Such a dictionary is also known as a memtable. Although this is not the only kind of index that you can use for such a purpose, it serves as a good starting point for more complex structures.
Given the fact that new entries are always appended to the file, we can use a dictionary that maps keys to the offsets of their last occurrences in the file. For example, if the store() operation for key ‘abc’ created an entry at file location 32, we can store the mapping of ‘abc’ to 32 in the dictionary. The benefit of doing so is that the next time the value for ‘abc’ is asked, we can use the dictionary to find the last occurrence offset, which is 32, seek to that location, and then read the value without scanning the entire file from the beginning to the end. This works naturally given our data format because updating a key does not require special treatment—it simply replaces the offset value for that key in the dictionary.
While a dictionary works great for speeding up lookup, the most apparent limitation for this method is that computers have limited memory(RAM), which means the dictionary cannot grow without bound. Eventually, the system would run out of memory and no new entries can be added to the dictionary, causing serious problems for the users.
Segmentation and Compaction

As you have probably noticed, the log stores redundant information about the keys because new entries are always appended and old ones are not removed. A good question to ask is: how do we avoid eventually running out of disk space? A good solution is to break the log into segments of a certain size and make subsequent writes to a new segment if the current segment reaches the size limit. A process called compaction can then be applied to these segments by throwing away duplicate keys in the log and only keeping the most recent update for each key. The result of compaction is we have smaller segments. We can then optionally merge these segments in the background without disturbing users of the database because older segments are never modified after a new segment is created.
PS: In real storage engines, the problem is a lot more complicated because they have to handle issues with concurrent executions, access control, and transactions.
SSTable
Recall that a log store key-value pairs in the order that they are written, and that values later in the log take precedence over values for the same keys earlier in the log. A Sorted String Table(SSTable) is a data format that is similar to the log format discussed earlier, however, the only difference is that it requires the entries to be sorted by key.
With SSTables, merging segments is simple and efficient because it can use a mergesort-like algorithm given the fact that entries are already sorted by key. If the same key appears on multiple segments, the value from the most recent segment is kept and the rest are discarded.
Another benefit of SSTable is that we can now use a sparse range index to look up a particular key in the file. Recall that we used a dictionary earlier to speed up key lookup, however, the drawback of using a dictionary that maps every key to every offset is that we might quickly run out of memory. With a sparse index, we can simply store the offsets for some of the keys instead of all of the keys. For example, say you want to look up the value for the key ‘monkey,’ but you do not know the exact offset for that key in the segment file. However, you do know the offsets for the keys ‘money’ and ‘mummy,’ and because of the sorting, you know that ‘monkey’ must appear between those two. What’s left is that you can just scan everything between the key ‘money’ and the key mummy' until you find ‘monkey’ if it exists. Additionally, by cleverly picking keys to include in the index, an SSTable can potentially enjoy the benefit of more efficient I/O reads if the keys in the index correspond to the start of blocks on disk.
Storage engines that are based on this principle of merging and compacting sorted files are often called LSM storage engines.
B-Tree
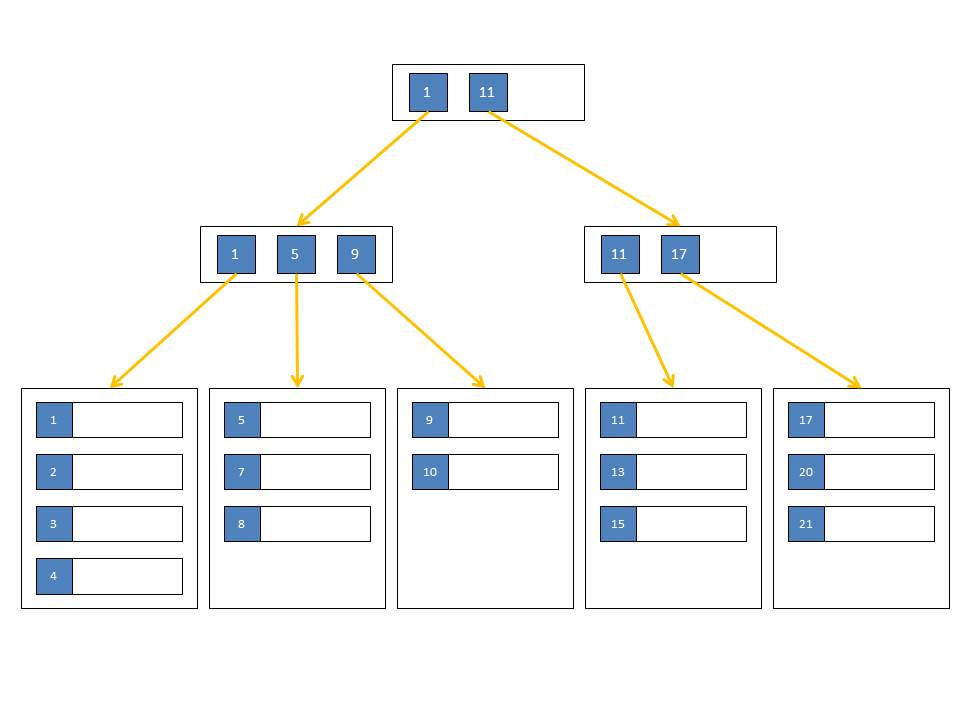
The log-structured indexes we saw earlier break the database down into variable-size segments. By contrast, B-tree is a data structure that breaks the database down into fixed-size blocks or pages, traditionally 4KB in size, and read or write one page at a time. This design corresponds closely to the underlying hardware, as disks are also arranged in fixed-size blocks. Storage engines that are based on B-trees are called page-oriented storage engines.
One page is designated as the root of the B-tree; whenever you want to look up a key in the index, you start here. The page contains several keys and references to child pages. Each child is responsible for a continuous range of keys, and the keys between the references indicate where the boundaries between those ranges lie.
The algorithm that updates the B-tree ensures that the tree remains balanced, which means a B-tree with n keys always has a depth of O(log n). Most databases can fit into a B-tree that is three or four levels deep, so you don’t need to follow more pages to get the data you need. For example, a four-level tree of 4KB pages with a branching factor(number of children) of 500 can store up to 256TB of data.
B-Trees vs LSM-Trees
LSM engines are the de facto standard today for handling workloads with large fast-growing data. The primary reason behind their success is their ability to do fast sequential writes (as opposed to slow random writes in B-tree engines) especially on modern flash-based SSDs that are inherently better suited for sequential access. On the other hand, B-trees usually grow wide and shallow, so for most queries, very few nodes need to be traversed. The net result is high throughput, low latency reads.
In general, LSM-trees are typically faster for writes, whereas B-trees are thought to be faster for reads.
Summary
Data is at the center of many challenges in system design today. As a developer, it is essential to have a good understanding of the underlying storage engines to reason about their performances. On the most fundamental level, a database needs to do two things: when you give it some data, it should store the data, and when you ask it again later, it should give the data back to you. Log-structured storage engines use files called logs to store data and use a hash index to speed up lookup. A page-oriented storage engine uses B-trees for index with the data stored in pages on disk. In general, LSM-trees are typically faster for writes, whereas B-trees are thought to be faster for reads.



Comments